This page explores the results of our MongoDB Vector Search performance benchmark.
Summary of Results
At 15.3M vectors using
voyage-3-largeembeddings at 2048 dimensions, MongoDB Vector Search with quantization configured retains 90-95% accuracy with < 50ms query latency.Binary quantization is slower when the number of candidates requested is in the hundreds due to the additional cost of rescoring with full fidelity vectors. However, at ~1/4 the price of serving the index, it might be a preferable option for many large scale workloads.
We recommend over 1024 dimensions when running larger workloads with quantization.
Selective filters can improve or worsen performance depending on the value selected for
numCandidates.The additional cost of rescoring for binary quantization shows up in reduced throughput when running highly concurrent workloads.
Sharding slightly improves throughput, but we still recommend scaling out number of Search Nodes or the number of available cores on a Search Node to improve throughput.
Recall and Latency Analysis Across Multidimensional Benchmark
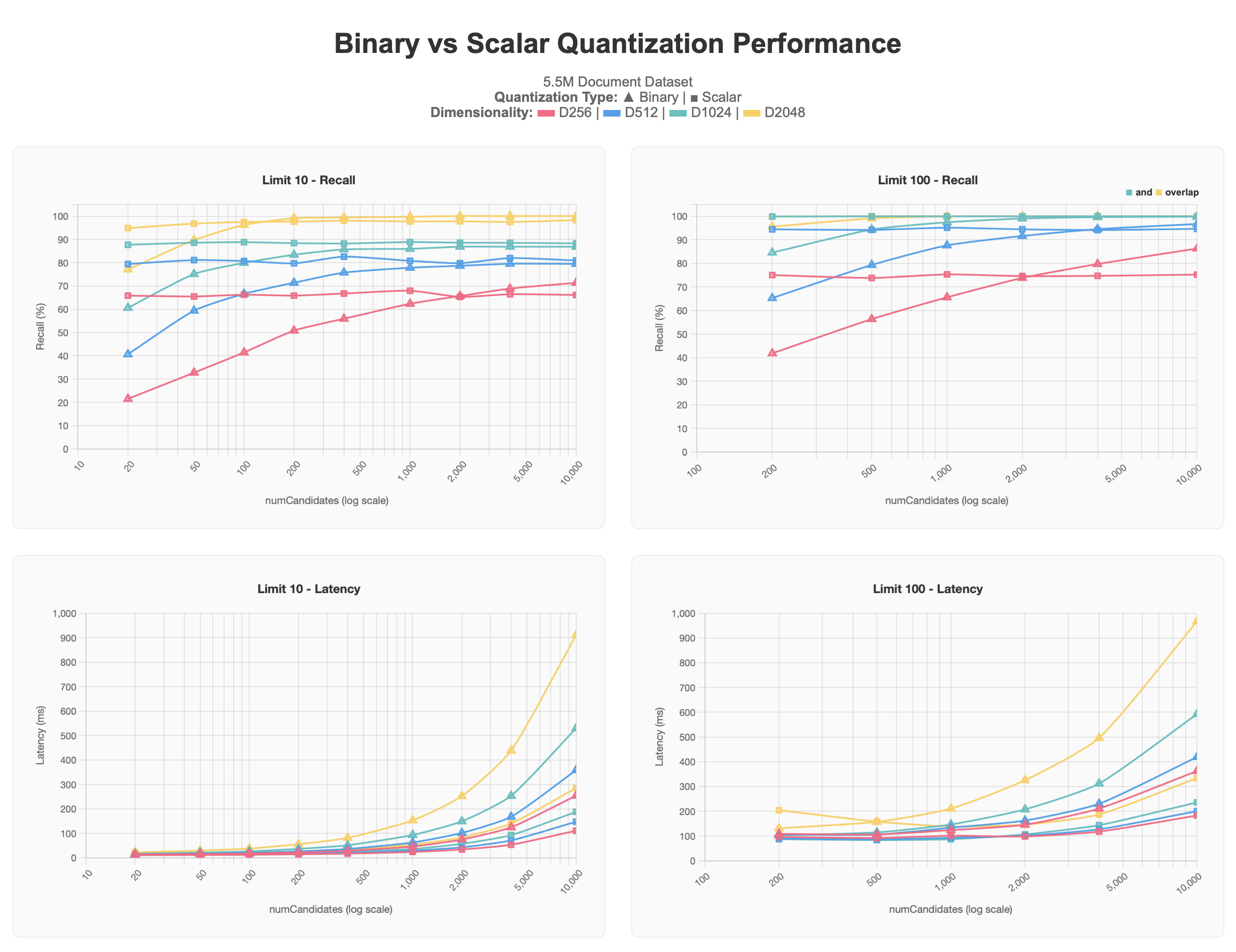
The first set of results shows the tests that we ran against a 5.5M document dataset
containing multiple dimensionalities of vectors (256, 512, 1024, 2048),
all produced using voyage-3-large, within each document.
To view the full chart, see the Claude artifact.
The scalar quantized results all start at higher levels
than the binary quantized results, but stay at their asymptotic level
even as numCandidates increases. Conversely, binary quantized queries
yield more accurate results as more numCandidates are requested,
approaching the asymptote of scalar quantization, and in some cases
passing it, at the cost of higher latency, particularly above
numCandidates of 1000.
Generally lower values of limit are harder to get closer to 100% accuracy
due to the top results being harder to pinpoint, and often might
require higher numCandidates to achieve better results. This is particularly
observable in the binary quantization plot. We can also observe that lower
dimensional vectors 256d and 512d particularly suffer at a large scale with
either form of quantization. 256d never exceeds 70% recall and 512d never
exceeds 80% recall in the limit 10 tests, with limit 100 requiring higher
values numCandidates to reach the 90-95% target zone.
Given this information, we determined that when working with a large dataset, we recommend having dimensionality of at least 1024d and applying quantization to scale than having lower dimensionality and not using quantization, with the amount of vectors requested for the use case playing a factor as well.
Larger Benchmark Results
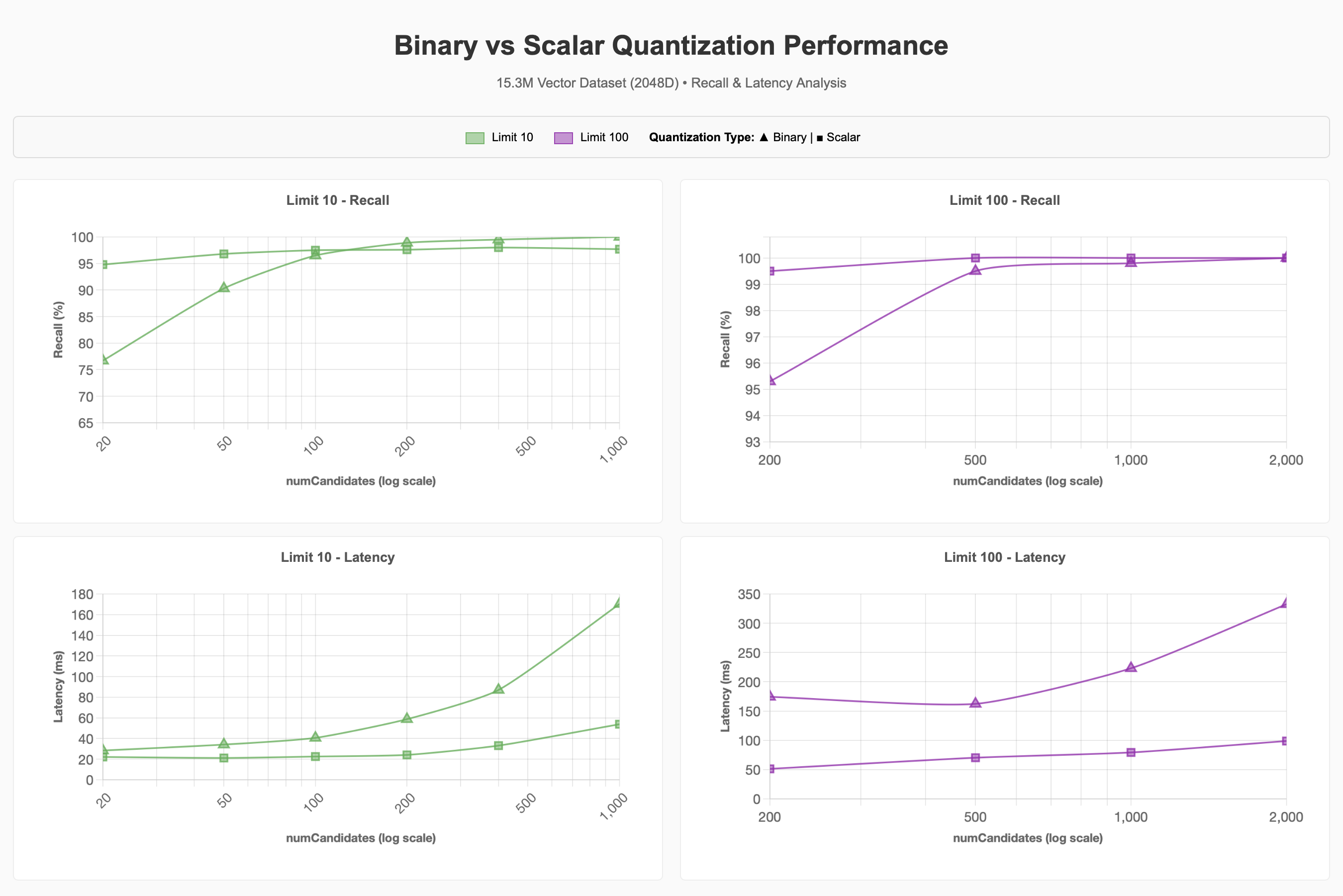
For the larger 15.3M vector dataset, we fixed the dimensionality to 2048d and examined the impact of quantization, filtering and concurrency on performance. We chose to pin on 2048d based on the results from the previous set of tests showing that higher dimensions retained recall in a more favorable manner, though 1024d would have likely served just as well to reach the 90-95% recall target.
Recall and Latency Analysis
We observed that it takes significantly more numCandidates when using
binary quantization to achieve the 90-95% recall target compared
to baseline. Higher numCandidates generally means higher latency,
but this might vary.
To view the full chart, see the Claude artifact.
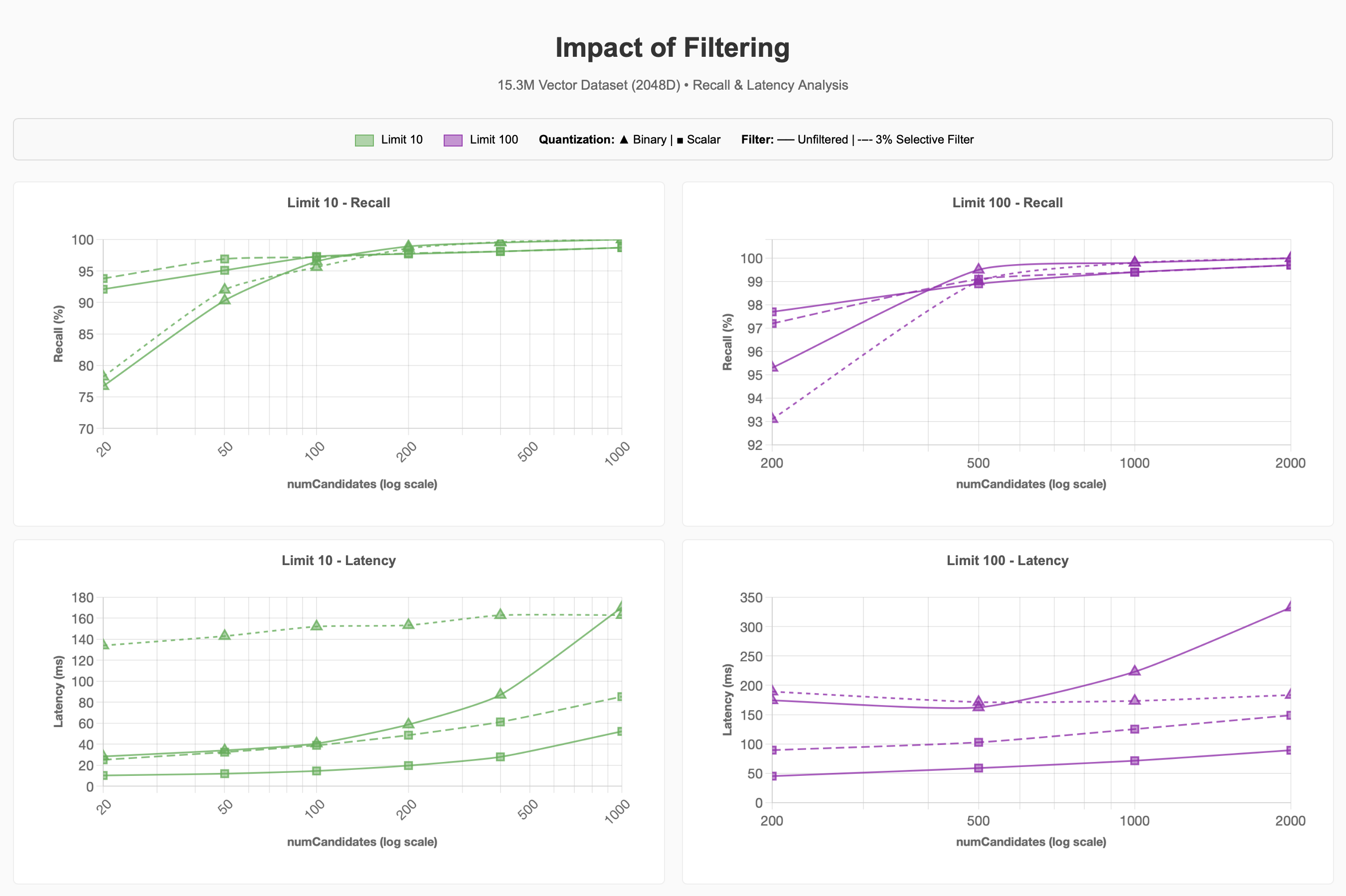
Filtering
We observed what happens to recall and latency when using a selective filter on the dataset for ~500k items of the 15.3M items are in the Pet Supplies Category (~3% of the corpus):
To view the full chart, see the Claude artifact.
We can see that the 3% selective filter can cause queries to be significantly
more expensive. For binary quantization at lower limit values, this
was roughly 4x as expensive to achieve 90-95% recall compared to the unfiltered
queries.
Future improvements in Lucene 10, which support Acorn-1 search strategies for Hierarchical Navigable Small Worlds, might improve this process. However, performing ENN when the number of requested candidates exceeds the number of vectors matching the metadata filter within a segment demonstrates that filter selectivity plays a large part in query performance, regardless of the selected quantization regime.
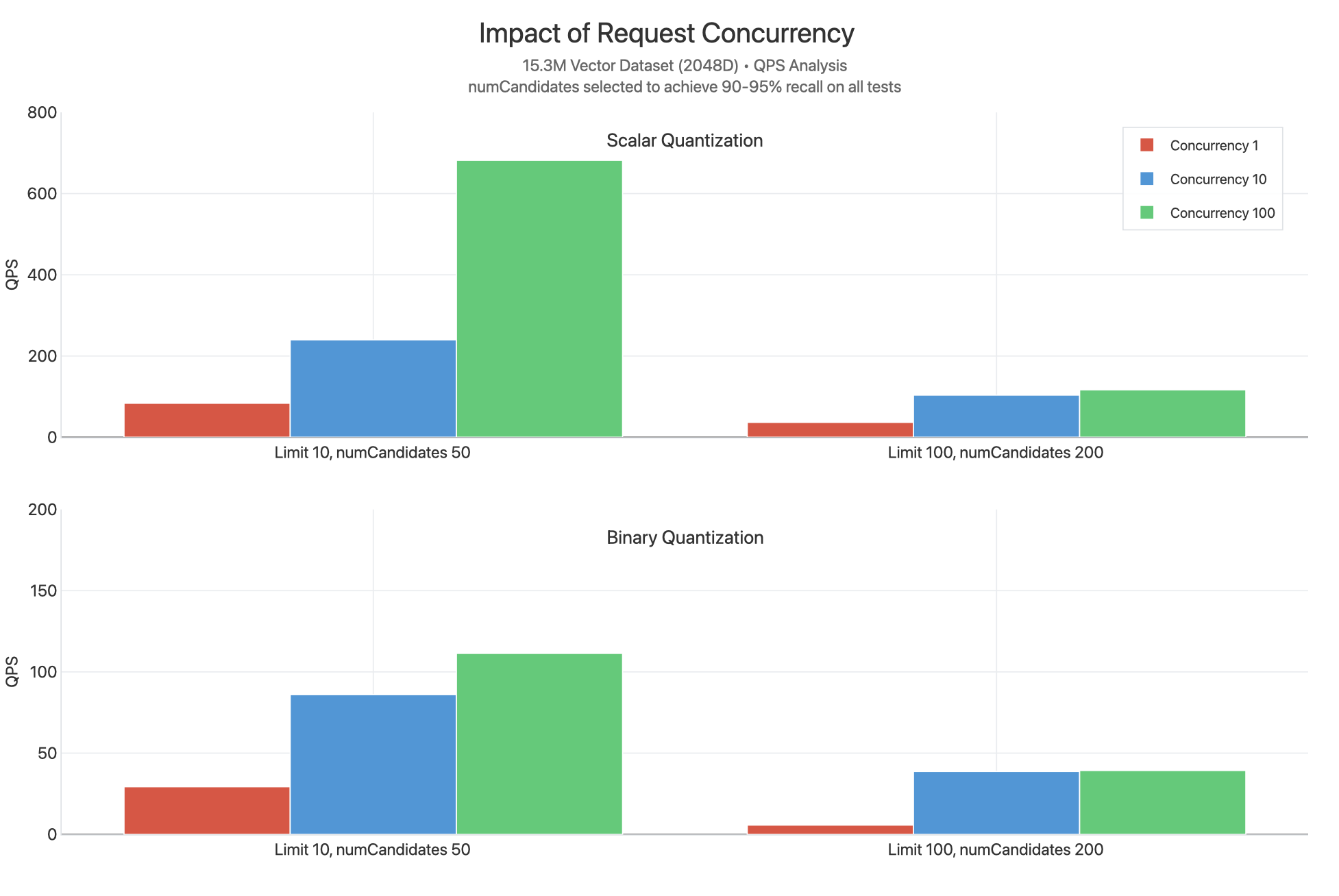
Concurrency
These tests scale concurrent requests between 1, 10, and 100 at the various
limit values when using scalar and binary quantization. numCandidates are
selected by choosing values that allow 90-95% recall to be achieved:
To view the full chart, see the Claude artifact.
We observe that scalar quantization achieves substantially higher QPS
at all values of limit, likely because less work is being done per query with
lower numCandidates and because rescoring is not being performed. We
observe substantial CPU bottlenecks occurring, as indicated by the concurrency
10 and concurrency 100 plots generally being very close to each other,
indicating that higher latency would be observed.
One exceptional data point is limit 10, concurrency 100 for scalar quantization
yielding significantly higher QPS. This is likely because of the lack of
rescoring and lower limit values means fewer comparisons are performed for this
query, allowing each request to return more quickly and make the cores
available to serve other queries.
Scaling out the number of available vCPUs to serve requests, either by scaling up the Search Node tier or scaling up the number of Search Nodes from the minimum of 2 up to 32 nodes might help resolve concurrency bottlenecks and allow you to scale well into the thousands of QPS.
Sharding
We also observed what would happen if the cluster and collection were sharded
(on _id) and unfiltered queries were issued against a binary quantized index.
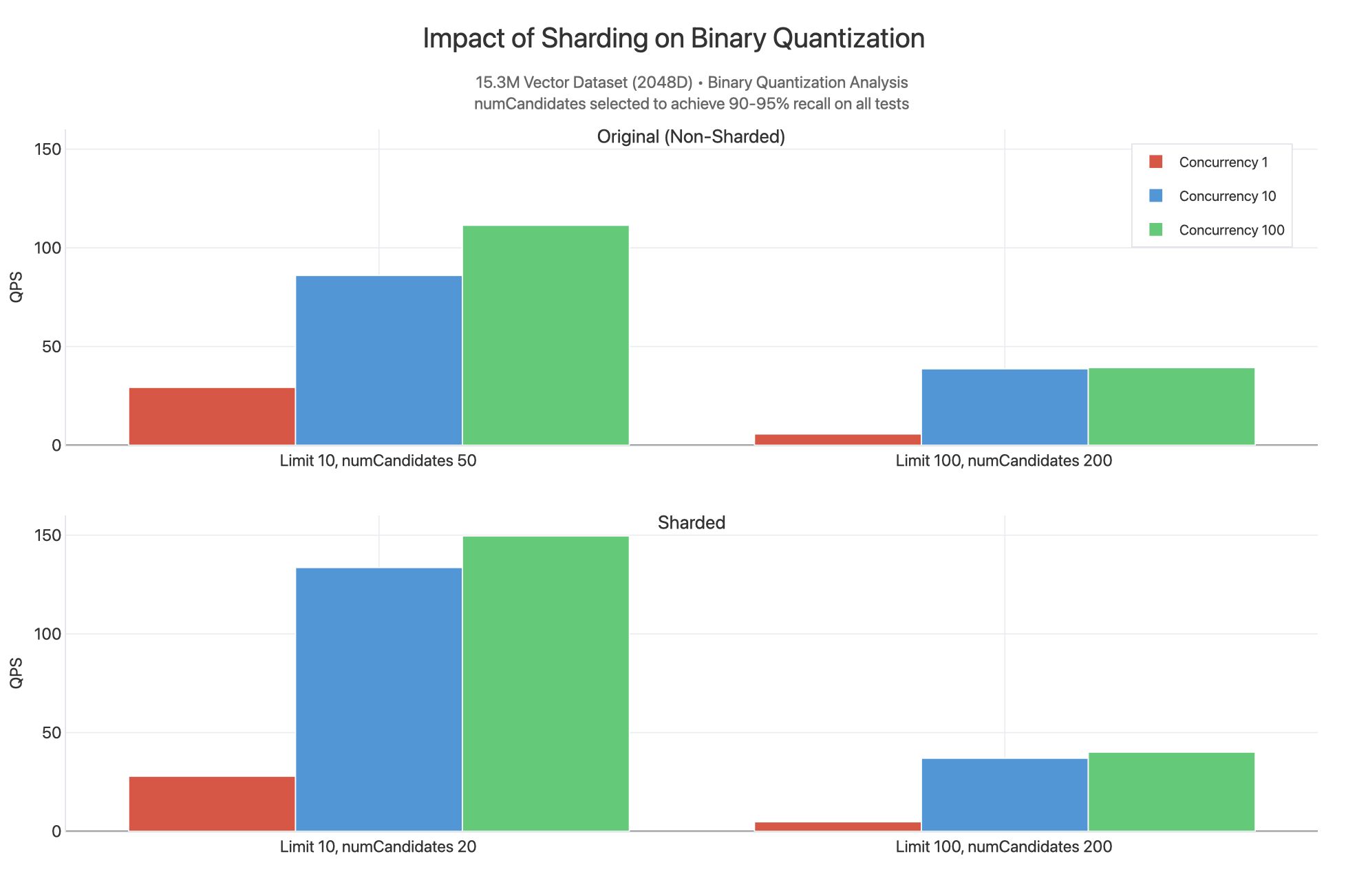
To view the full chart, see the Claude artifact.
Here, we see that the sharded results have a higher QPS at limit 10 as the
lower value of numCandidates can be provided to produce results in the
90-95% recall range. This is because the 15.3M dataset is split across three
shards, each of which have their own indexes filled with 5.1M vectors spread
across segments containing HNSW graphs. We are functionally doing a less
advanced search where it is more likely that each query scatter gathered across
3 shards simultaneously could find the closest n vectors. For this reason,
the QPS is slightly higher when sharding since you can reduce numCandidates
and have more cores available to serve queries, but the difference is not as
significant to justify the increased cost of sharding the cluster. Most often
you should shard your cluster for reasons related to your operational workload,
not because you need to scale throughput for vector search.
Note
The values are similar for limit 100, numCandidates 200.
We might expect this to perform better for filtered queries with an
intelligent shard key matching used as a filter.